Evaluation: Beyond AUC
The framework cannot be evaluated using the benchmarks that dominate deepfake detection research. Existing benchmarks test classifiers on isolated clips and report binary accuracy or AUC. AUC remains useful for evaluating media-classification subcomponents, but is insufficient as a primary summary for interaction-grounded deception: it averages over operating points, is invariant to deployment base rates, and reduces latency to a single number. We propose evaluating defences on complete interaction scenarios using four complementary metrics that surface these dimensions explicitly.
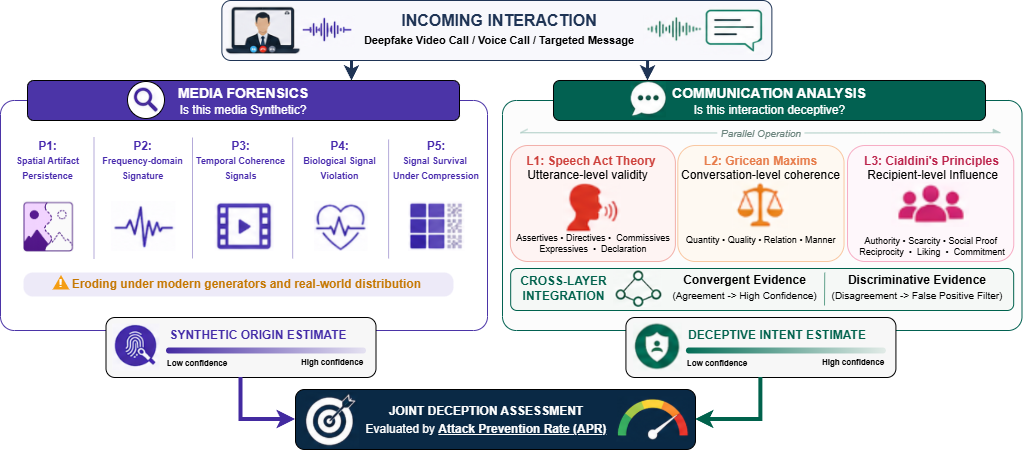
Attack Prevention Rate (APR)
The fraction of attack scenarios in which the defence intervenes before the target executes the requested harmful action. Correct decisions issued after compliance contribute nothing to APR.
Benign Pass-Through Rate (BPR)
The fraction of legitimate interactions that proceed without unwarranted intervention. APR alone is gameable — a defence that intervenes on every interaction trivially achieves APR = 1 — so we pair it with BPR. A useful defence achieves both, with their trade-off made explicit on the APR–BPR plane.
Precision at fixed APR
The proportion of flagged interactions that are genuine attacks, evaluated at a chosen attack prevention rate and under deployment-realistic base rates. Because deepfake fraud has very low base rates in deployment, even high BPR can mask operationally untenable false-positive volumes at scale. Precision at fixed APR surfaces this cost directly.
Intervention latency
The time elapsed from the start of an interaction to the system's intervention decision (block, alert, or escalation). A defence achieving high APR at 60 seconds is qualitatively different from one achieving the same APR at 5 seconds in attacks where compliance occurs within ten seconds. Latency must be reported alongside APR and BPR, not collapsed into them.
Scenario design
Scenarios should be characterized along five dimensions: attack type (CEO fraud, invoice redirection, phishing escalation), victim persona (finance, HR), modality and channel (audio, video, synchronous or asynchronous), interaction length (single or multi-step), and compliance setup (scripted decisions, simulated agents, or human studies). A useful benchmark may include 102–103 scenarios across ~10 attack types, ~5 personas, and 2–3 modalities, with matched benign cases for BPR.